

Premessa
Open source e software libero: due termini spesso accomunati fino talvolta a confondersi, due termini dei quali forse sentiremo parlare più insistentemente in futuro visto anche il successo elettorale di un movimento che, in qualche modo, si richiama ad essi.
Per inciso, ultimamente, al comune di Milano è stata approvata una mozione per favorire nell’amministrazione l’implementazione di tale tipologia di software: Mozione Open Source Comune Milano_12 02 29
Dico subito che, nella sostanza, si tratta di due termini decisamente diversi, direi nemmeno commensurabili, essendo il primo di natura tecnica mentre il secondo è essenzialmente morale-filosofico, nella pratica tendono spesso ad essere usati come sinonimi anche perché il software libero ingloba comunque l’open source.
Pur rimanendo in ambito divulgativo, mi sono lungamente interrogato sul taglio da dare a questo articolo, ma alla fine, poiché, ricordando un detto non mio, forse un po’ retorico ma profondamente vero:
la strada verso la libertà è erta e difficoltosa e il suo prezzo in sacrificio e sudore è sempre alto
ma non esiste scorciatoia
ho ritenuto di affrontare l’argomento con un minimo di dettaglio, sperando che ciò non sia troppo tedioso per chi già è al corrente dell’argomento o troppo impegnativo per chi gli si avvicina per la prima volta.
In ogni caso mi perdonino i puristi se talvolta non sarò rigoroso, ma lo scopo penso giustifichi ampiamente alcune imprecisioni per altro non sostanziali.
Le parti scritte in questo colore sono aggiuntive e non essenziali al fine della comprensione dell’argomento, ma la loro lettura è comunque consigliata.
Sistemi di numerazione
Con due mani e dieci dita, l’uomo ha naturalmente sviluppato nel tempo un sistema di numerazione decimale, nel quali i dieci simboli, da zero a nove, rappresentano altrettante cifre combinando le quali si possono rappresentare tutti i numeri.
Su questo sistema, a base 10, sono stati sviluppati tutta una serie di metodi di calcolo nonché di strumenti che facilitano l’esecuzione della varie operazioni.
Il massimo numero ottenibile con una cifra è 9, che è uguale a 101 – 1, usando invece due cifre il massimo è 99 = 102 – 1 etc..
Per i più curiosi la formula generale è la seguente:
M = 10n – 1
dove M è il massimo numero ottenibile e n il numero di cifre usate.
I numeri ottenibili sono invece 10n, contando anche lo 0.
Va da se che si possono pensare sistemi di numerazione a base diversa, i ragni opterebbero sicuramente per la base 8, aracnidea, tante infatti sono le loro zampe, in modo analogo gli insetti, o esapodi, non avrebbero dubbi nel scegliere il numero 6.
Peraltro nel sud della Francia era in uso un sistema ventesimale: evidentemente furono prese in considerazione anche le dita dei piedi.
La base più semplice possibile è senz’altro quella binaria che usa il 2, in questo caso con una cifra (digit) il massimo numero ottenibile è 1 = 21 – 1, con due è 3 = 22 – 1 etc.
La formula è: M = 2n – 1.
Mentre la formula più generale è: M = bn – 1 dove b è la base (maggiore o uguale a 2).
I numeri in base 2 si presentano come sequenze di uni e zeri.
Ad esempio, mettendo la base a pedice: 102 = 210, 10102 = 1010, etc..
Altre due basi di interesse in informatica sono l’ottale (8), e l’esadecimale (16), in questo caso i simboli sono 16, cioè quelli del decimale seguiti dalla A (10 decimale) fino alla F (15 decimale).
Sarà chiaro in seguito perché la base 10 non ha alcun interesse per i computer (naturalmente il computer non ha interessi: è una macchina!), si noti però come un numero tondo come 1010 non corrisponda ad un altrettanto tondo come potrebbe essere 10002.
Algebra binaria
Il sistema di numerazione a base due o binario si presta anche a operazioni logiche molto semplici, basta associare 0 al falso e 1 al vero, ed introdurre alcuni tipi di operatori detti appunto logici.
E’ nata così nell’800′ una logica binaria: l’algebra di Boole.
Mi piace ricordare il matematico irlandese fondatore della logica matematica e di questa in particolare: George Boole (1815-1864), il cui testo fondamentale (An investigation of the laws of thought) è del 1854 praticamente ben cent’anni prima della nascita del calcolatore elettronico!
L’algebra di Boole fa uso di appositi operatori, ad esempio l’operatore OR (O): applicato a due proposizioni da il risultato vero se almeno una delle due è vera.
Logica interna del computer
Nel modo più essenziale possiamo considerare l’elemento principale del computer, la CPU (central processing unit), come un dispositivo elettronico atto ad eseguire operazioni booleane.
Lo zero e l’uno sono pensabili come ottenuti elettricamente con un interruttore (switch) che ha due stati: aperto (0) o chiuso (1), mentre la CPU è un insieme di milioni di tali interruttori.
Questi interruttori nati come valvole, diciamo quelle delle radio d’anteguerra, naturalmente sono nel tempo divenuti sempre più piccoli e meno energivori, fino ad arrivare ad esserne contenuti a milioni in un pezzettino di silicio (silicon), più piccolo di un’unghia.
In base alle posizioni degli interruttori, che commutano velocemente seguendo un programma, vengono eseguite tutte le operazioni, su numeri a loro volta memorizzati su batterie di interruttori, cioè i vari tipi di memoria.
Il programma che viene eseguito, così come i dati su cui lo stesso agisce, devono essere capiti dalla CPU e quindi scritti nell’unico modo possibile cioè in binario.
Uso il termine capire, ma, deve essere chiaro che la CPU non capisce nulla, almeno nel senso umano del termine.
Quello che la CPU legge ed esegue è dunque una lunga sequenza di numeri binari, che sono o istruzioni o dati, qualcosa del genere:
01100101
00100101
11100101
00100100
……..
Sequenza che può contenere migliaia, centinaia di migliaia ma anche milioni di righe.
Si noti come, ai fini di operare booleanamente, è sufficiente avere qualcosa che possa essere in due stati ben distinti, infatti, nella realtà, gli interruttori, nella CPU, sono infinitesime cellule di silicio che possono essere a due livelli di tensione uno basso (0) e uno alto (1).
Nel CD registrato gli uni sono ottenuti con il passaggio della luce attraverso fori infinitesimi bruciando, con un laser a bassa potenza, lo strato interno, assimilabile ad un stagnola, mentre gli zeri corrispondono alla mancanza di foro, cioè il buio.
Le operazioni che può fare la CPU sono in realtà semplicissime, già la divisione è sorprendentemente complicata, le esegue però in modo strabiliantemente veloce attraverso dispositivi superminiaturizzati.
In pratica gli interruttori possono commutare il loro stato alla frequenza di clock (orologio), oggi arrivata a Ghz, dove 1 gigahertz = un miliardo di commutazioni al secondo.
La definizione di computer come velocissimo stupido è dunque tutt’altro che campata per aria.
Non c’è quindi nulla di misterioso o esoterico nella macchina pc, se mai c’è da rimanere affascinati da personaggi come Boole, e del suo allievo De Morgan, che, per pura elucubrazione mentale, hanno fornito un elegante e rigoroso mezzo matematico alla base del funzionamento di macchine del futuro (allora) che il continuo e spettacolare progresso tecnologico ha reso sempre più piccole, di facile uso e alla portata di tutti, o quasi.
Per riassumere possiamo impropriamente affermare che il computer, o meglio CPU, ragiona, cioè esegue un programma, applicando l’algebra di Boole ai soli numeri che capisce che sono appunto quelli binari.
Linguaggi di programmazione
Come già accennato una delle caratteristiche del computer è quella di eseguire programmi, ovvero sequenze di istruzioni logiche-matematiche memorizzate da qualche parte, tipicamente un disco rigido, agendo su dati memorizzati su opportuni supporti, dischi, card oppure provenienti da porte opportune, sensori, registratori etc..
La lingua che si usa per programmare costituisce un linguaggio.
Ne esistono moltissimi a cominciare dai primi, che erano essenzialmente numerici, linguaggi macchina, passando all’assembly fino a quelli di alto livello.
Linguaggi macchina
I primi computer, serie di armadi inaffidabili, voraci d’energia e costosissimi, venivano programmati in binario, da uomini che dovevano avere una grande pazienza (i cosiddetti real programmers), il tutto risultava comunque ostico e incomprensibile per chi non avesse scritto personalmente il programma, e, probabilmente, anche chi lo aveva steso dopo poco se lo dimenticava: la mente dell’homo sapiens non è binaria!
Se creò quindi un primo programma, scritto in binario, che si occupava di convertire listati composti da numeri a base 8 in binario, di conseguenza la stesura del programma e avveniva in ottale.
Il termine byte viene quindi da questo momento informaticamente preistorico, infatti essendo il bit una cifra in binario (ovvero uno 0 o un 1) il byte risulta composto da 8 bit.
Quindi un byte può rappresentare un numero decimale che al massimo è: 28-1 = 255.
Per un ulteriore miglioramento si stese un primo programma, in ottale, che traducesse numeri esadecimali, a base 16, in numeri binari, rendendo possibile la programmazione in esadecimale.
Si può ora capire l’uso di tali tipi di base: sia 8 che 16 sono potenze di 2 e quindi il passaggio da numeri in tali base al binario è facile e tondo.
Per inciso da qui viene per esempio il termine KB (1024 byte) infatti è: 210 = 1024 bytes, ovvero 8192 (1024×8) bit, e ecco perché se un 1 Kg è 1000 grammi lo stesso non vale per il KB.
Linguaggi assembly
Anche questo modo di programmare non poteva essere soddisfacente, la mente umana non è esadecimale e lunghe sequenze di tali numeri non sono facili da legare immediatamente alle funzioni del programma ed al suo funzionamento.
Fu quindi fatto un passo fondamentale creando, in esadecimale, un programma che permettesse di tradurre in binario un listato scritto in un modo simbolico il famoso o meglio famigerato assembly, talvolta detto impropriamente linguaggio macchina, dove le istruzioni sono delle abbreviazioni di comandi in Inglese tipo:
LDA = load accumulator (carica l’accumulatore)
JMP = jump (salta)
L’assembler è il software, cioè un programma, che legge il listato, scritto appunto in assembly, e lo traduce in binario, ovvero lo assembla.
Sinteticamente possiamo dire l’assembler legge queste lunghe serie di istruzioni traducendole in binario.
Un ulteriore passo fondamentale fu quello di rendere possibile scrivere dei commenti nel listato assembly, in modo tale che il programma stesso fosse comprensibile anche per altri programmatori e aiutasse a ricordare, anche allo stesso sviluppatore, quello che aveva fatto.
Questi commenti, che non vengono tradotti in binario e quindi si perdono in fase di assemblaggio, in qualche modo si possono paragonare alla parte descrittiva in un compito di fisica o matematica, essendo la parte di programma le formule e lo svolgimento dei calcoli.
In genere da queste parti discorsive, che difficilmente lo studente copia in un compito in classe, si può intuire quanto lo svolgimento del problema sia farina del sacco dello scolaro stesso.
Poiché la corrispondenza fra le istruzioni e il relativo numero binario è biunivoca, è relativamente facile scrivere un programma (disassembler) che faccia il percorso inverso, cioè dal listato in binario torni al listato in assembly originale.
Ad esempio lda corrisponde a 01010100 cioè a 168 decimale.
Si noti però, che in ogni caso, i commenti vengono irrimediabilmente perduti nella riconversione rendendo talvolta difficile, anche per esperti, comprendere il funzionamento del programma.
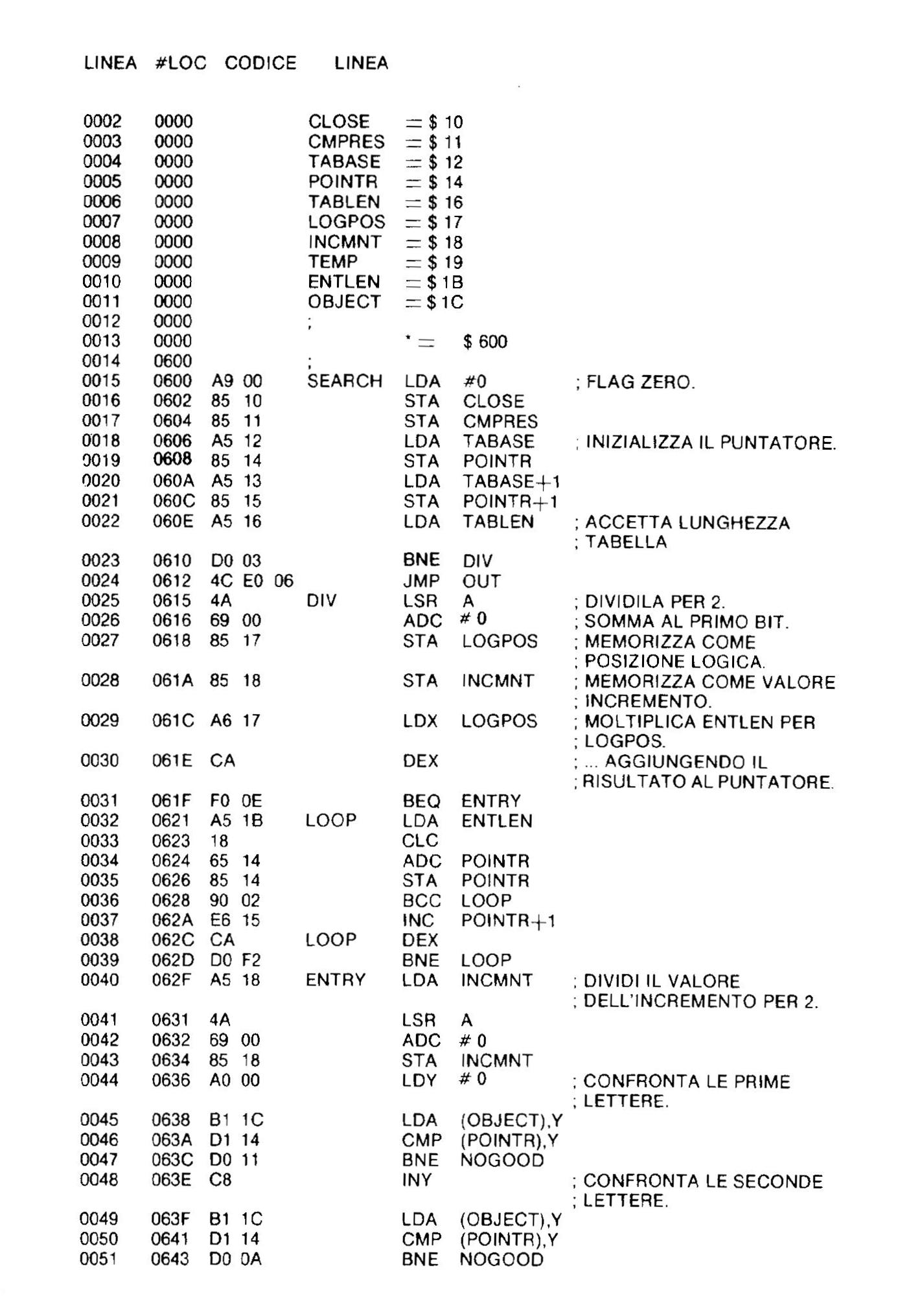
A titolo esplicativo si riporta una parte di un listato assembly in cui sono presenti anche i commenti:
Per la cronaca trattasi di una parte di listato assembly per il 6502, CPU del CBM20 e CBM64, per inciso ogni famiglia di microprocessori ha il suo set di istruzioni assembly.
Naturalmente non è facile capire un listato del genere, è però intuitivo comprendere come esso sia estremamente meno difficoltoso, per chi conosce l’assembly, rispetto a una lunga sequenza di numeri esadecimali o, addirittura di zeri ed uni.
I più curiosi noteranno come la terza quarta e quinta colonna siano il listato esadecimale del programma in assembly.
In settima colonna troviamo il codice di operazione, che è semplicemente l’abbreviazione di un comando in Inglese, nell’ultima colonna, dopo il punto e virgola, si trovano i commenti, qui in Italiano, che sono una vera e propria manna per chi vuole capire velocemente il modo di operare e lo scopo del programma.
Linguaggi d’alto livello
Malgrado gli enormi passi in avanti la programmazione in assembly rimane difficoltosa e implica che il cervello umano si deve mettere, in qualche modo, a ragionare come la macchina.
A tutt’oggi l’assembly è raramente usato e i relativi sviluppatori sono sempre più rari, ma all’inizio era di impiego quasi obbligatorio dove fosse necessario ottimizzare la velocità di esecuzione e sfruttare la poca memoria disponibile ed ottimizzare il funzionamento della macchina.
Fu quindi fatto un ultimo passo, cioè un programma, scritto in assembly, che traducesse un listato scritto in un linguaggio, cosiddetto di alto livello, vicino al cervello umano, di conseguenza astratto e in qualche modo lontano dalla macchina.
Questo programma si chiama compilatore (compiler), e ogni linguaggio ha il suo.
Un linguaggio consiste in proprie regole ortografiche e sintattiche, che vengono tradotte in binario da un apposito compilatore.
Fra i primi linguaggi ricordiamo il FORTRAN, per scopi scientifici, il Cobol di uso finanziario etc..
Un linguaggio che mi piace ricordare è il C perché usato in un software fondamentale per lo sviluppo di sistemi liberi, uno dei suoi due autori, Dennis Ritchie, è deceduto, nel più assoluto silenzio mediatico, nell’ottobre del 2011, periodo in cui proliferavano in tutti i mezzi di informazione, nazionali e mondiali, i peana per Steve Jobs, scomparso nello stesso mese:
Jobs vs. D.Ritchie, Tributo a D.Ritchie di B. Kernigan.
Il listato di un programma scritto in un linguaggio d’alto livello, malgrado quello che possa sembrare, è molto più facile da comprendere, naturalmente è necessario sapere il linguaggio, ne più ne meno come la conoscenza della lingua tedesca è imprescindibile per leggere un testo in Tedesco.
Naturalmente se si vuole comprendere le funzionalità e gli scopi del programma è obbligatorio conoscere abbastanza bene l’argomento, ad esempio: chi non sa cosa sono le equazioni differenziali, non potrà mai comprendere il funzionamento di un programma che le risolve, per quanto conosca il linguaggio con cui è scritto!
Ovviamente anche i linguaggi d’alto livello si sono sempre più evoluti diventando sempre più potenti ed astratti, per altro è anche da notare che il sogno di un linguaggio universale sembra tramontato, e quindi ogni linguaggio è tendenzialmente destinato a ben specifici scopi.
Anche i mezzi di programmazione si sono sempre più evoluti, come apposite interfacce, editor che correggono gli errori grammaticali così come i moderni software di scrittura sottolineano o correggono le parole non corrette etc. etc..
Deve però rimanere chiaro che, a concludere e nella sostanza c’è, ad un certo momento, il passaggio, magari non trasparente, attraverso lo specifico compilatore.
A titolo esplicativo riporto un listato di un programma in Pascal il cui scopo è chiaro nei commenti.

Va da sé come le pizzerie procedano bene anche senza tale software!
Le parole chiave dei vari linguaggi sono in Inglese essendo stati sviluppati, almeno i primi, nel mondo anglosassone e comunque è considerabile ormai la lingua franca in campo informatico.
Differentemente dall’assembly il passare dal binario al listato originale nel linguaggio d’alto livello è una operazione molto difficile e, sostanzialmente, quasi impossibile, in ogni caso i commenti, fondamentali per la comprensione delle funzionalità e del modo di procedere, sono comunque irrimediabilmente persi.
Come esempio ulteriore si può pensare di fare tradurre un testo originale dal Tedesco al Latino, affidando quest’ultima versione a un buon traduttore, che ovviamente non conosca il testo iniziale, per riportarla nella lingua originale, ebbene: sicuramente il suo prodotto in Tedesco non sarebbe mai uguale al testo originario.
Immediato è capire come per un programmatore (anche sviluppatore) è invece facile, avendo il listato originale, molto meglio se commentato, eseguire sullo stesso correzioni, aggiunte, adattamenti etc., attività che non sono invece possibili avendo solo il listato in binario.
Si noti come, una volta formulato un certo linguaggio d’alto livello, da questo si possa generare altri linguaggi di alto livello, non è necessario, in generale, scrivere ogni linguaggio in assembly!
Open source
Possiamo ora dare alcune definizioni che, in base a quanto trattato, saranno chiare:
il listato di programma nel linguaggio d’alto livello si chiama codice sorgente (source code) o semplicemente sorgente
la compilazione è l’operazione viene eseguita da un apposito software, il compilatore, sul sorgente per ottenere una sequenza binaria che sia eseguibile dal computer
il risultato della compilazione si chiama codice oggetto (object code) o codice binario o codice eseguibile (executable code), oppure, più sbrigativamente: oggetto, binario o eseguibile.
Ricordando che per software si intende in generale un programma o codice, possiamo finalmente definire:
un software si dice
open source
quando il suo codice sorgente è reso disponibile
invece un software è
closed source
o proprietario quando ciò non avviene
Non esiste un binario senza sorgente, ma, solo quando esso è reso disponibile, magari a certe condizioni, si può parlare di open source.
Per inciso, anche se certi programmi sono quasi opere d’arte, gli sviluppatori non distruggono il sorgente come fanno gli artisti con le matrici di stampa o i modelli di fusione!
Estensione del significato di open source
Fino ad ora abbiamo parlato di programmi, stesso concetto può applicarsi a insiemi di dati (file) che possono essere disposti in modo reso noto oppure tenuto nascosto.
Il tipo di file, così intendendo un qualsiasi assieme ordinato di numeri binari, si riconosce, semplificando, dalla estensione, ovvero quella sigla che talvolta si vede alla fine del nome preceduta da un punto.
L’estensione, o formato, stabilisce il modo con cui è memorizzato il file, così .exe indica un file eseguibile, diciamo un programma, nei sistemi Windows (in Linux sono .bin), .doc indica invece un file di testo in formato Office, mentre .odt è un formato testo in Libre Office (già OpenOffice), in campo musicale ricordiamo il notissimo .mp3 e il meno noto .ogg.
Di formati ne esistono centinaia, forse migliaia, comunque possono essere divisi in:
formati proprietari o chiusi per i quali non viene resa nota la
modalità di memorizzazione (codifica)
——————–
formati non proprietari o aperti per i quali sono rese
pubbliche tali modalità
In generale, avendo un file in formato proprietario, è difficoltoso aprirlo o gestirlo se non con un software scritto da chi conosce nei minimi dettagli la codifica, infatti è molto difficile risalire alla codifica, avendo solo il file stesso, che, ricordiamolo ancora, è una sequenza di numeri in binario.
Analogamente succede con la modalità di formattazione, file system, dei supporti di memorizzazione (dischi fissi, pennette e quant’altro), ad esempio Windows usa il file system proprietario NTFS (new technology file system) mentre Linux ne adotta di aperti come EXT3 o EXT4, le pennette usb sono in genere formattate con Fat32, vecchio file system di Windows.
Anche in questi casi risulta difficile, per chi non conosce nei minimi dettagli le modalità di formattazione, leggere o memorizzare un file qualsiasi su un disco formattato con un file system proprietario.
Un esempio
Dovrebbe essere chiaro che, fornendo solo il binario, è possibile nascondere in esso parti di codice malevolo, virus, spie etc., viceversa, il possesso del sorgente permette molto più facilmente di scoprire l’intruso.
Questo è un esempio di virus:

Per uno sviluppatore risulta molto facile capire lo scopo di questo virus, ma anche per chi avesse solo un minimo di consuetudine con i termini informatici, e sono moltissimi, la presenza nell’ultima riga di format c sarebbe un buon motivo per insospettirsi, e infatti, questo virus, quando va in esecuzione, formatta il disco C cancellando irrimediabilmente tutti i dati ivi contenuti.
Viceversa, avendo solo l’eseguibile di un pacchetto software, è molto difficile trovare qualche decina di cifre in binario in cui si è trasformato il listato del virus, essendo le stesse affogate, magari diviso in parti, in milioni di cifre componenti l’eseguibile.
Questa per inciso è una delle ragioni per cui è più difficile infettare software open source.
A questo proposito i cosiddetti software antivirus, normalmente closed source, sono paradossali, infatti è come curare una polmonite con un antibiotico di cui non si conosce la composizione!
Nella seguente figura viene sintetizzato tutto quello che è stato spiegato, sulla destra c’è il sorgente, in mezzo lo stesso in assembly e a sinistra il prodotto finale dell’assemblaggio o della compilazione, cioè il binario.
Quella che per la macchina è una sequenza logica e capibile nei minimi dettagli è, per l’uomo, una accozzaglia sconclusionata e incomprensibile di zeri e uni.
Per inciso l’eseguibile risulta praticamente impossibile da capire anche per chi ha sviluppato il sorgente: ormai il binario è sconosciuto agli stessi programmatori, e giustamente!

Conclusioni
Potremo quindi riassume in questo modo:
il computer ragiona con numeri binari, esegue quindi programmi composti da sequenze di numeri in base 2 , agendo su dati memorizzati sempre in binario.
L’homo sapiens è invece lontano da tale modo di agire e preferisce avere a che fare con testi scritti in linguaggi evoluti.
Il compilatore è un programma che traduce in binario il codice scritto nel linguaggio evoluto.
Se si vuole in qualche modo agire sul programma, correggendolo, modificandolo, aggiungendovi nuove funzionalità, scoprirne gli intrusi o comunque studiarne il funzionamento, è assolutamente necessario avere il codice sorgente.
Analogo dicasi per il formato dei file e la formattazione dei supporti di memorizzazione.
La disponibilità del sorgente da, in definitiva, la libertà tecnica allo sviluppatore, cioè qualsiasi sviluppatore, purché sufficientemente esperto nel linguaggio in cui è scritto il sorgente stesso.
I software, per i quali sono resi disponibile i relativi codice sorgenti si dicono
open source
o a sorgente aperto o aperti o non proprietari
———————-
Viceversa quelli che non danno il sorgente si dicono
closed source
o a sorgente chiuso o chiusi o proprietari
di Tullio Bertinelli
Linkografia
Naturalmente sul web esistono moltissimi link ai vari argomenti trattati, il rischio è di avere troppe informazioni, qui sono riportati solamente quelli richiamati dal testo
Mozione Open Source Comune Milano_12 02 29
http://www.youtube.com/watch?v=5Cl270D_Zbo
http://www.youtube.com/watch?v=uxtKwJZbYr0





aprile 16th, 2013 at 08:14
L’articolo spiega in modo chiaro ed esauriente il concetto di open source, aspetto con ansia il seguito, dove immagino verrà affrontato il “nocciolo” della questione, ossia come conciliare le logica commerciale che prevede di proteggere il frutto del proprio lavoro e dei propri investimenti, con aspetti etico-filosofici. Forse una soluzione come quella adottata per i farmaci dove viene fissato un limite di tempo per lo sfruttamento commerciale? All’autore l’ardua sentenza…