Ricerche condotte recentemente dal MIT hanno portato all’implementazione di una cosiddetta “Data Science Machine”, un software per l’interpretazione dei big data che potrebbe rivoluzionare il modo di analizzare dati e fare previsioni su future tendenze di mercato, ricerche scientifiche e comportamenti umani.
Data Science Machine
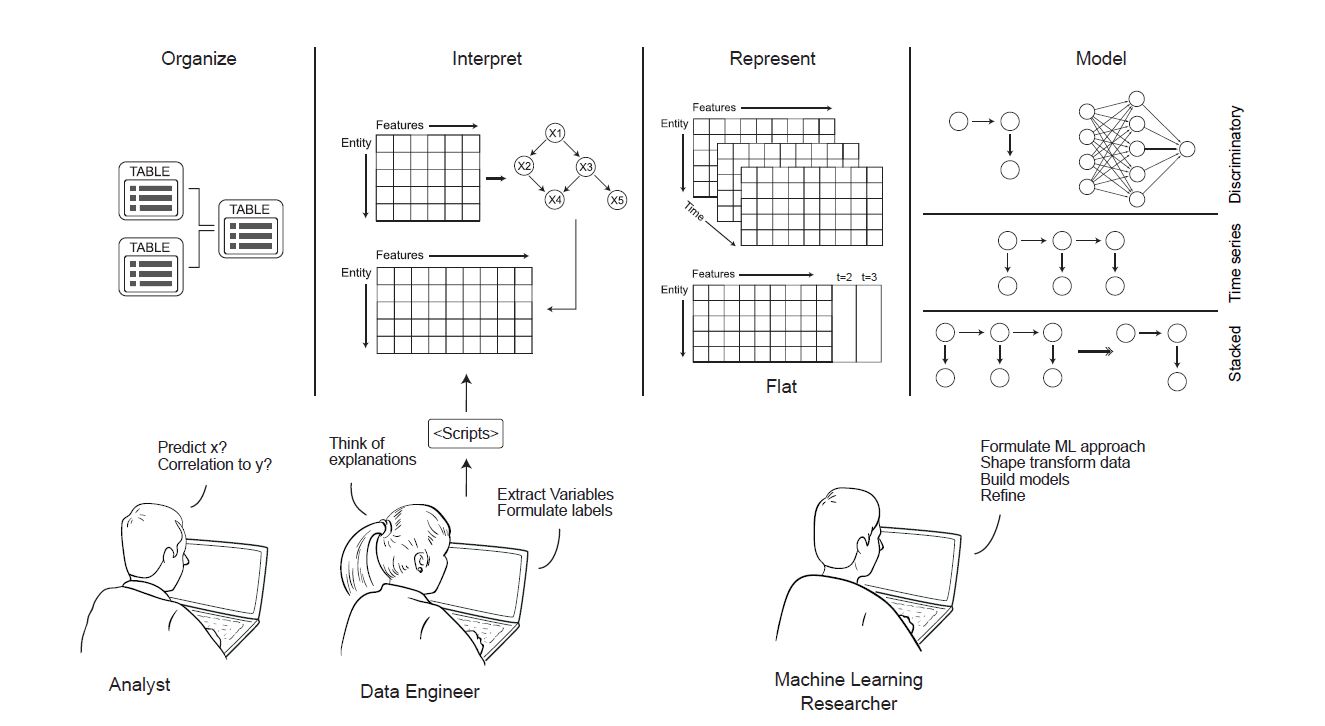
Questa macchina può essere descritta brevemente con le parole di uno dei due ricercatori del MIT che l’hanno ideata, Max Kanter, il quale la definisce come un “sistema automatizzato per la generazione di modelli predittivi basati su dati grezzi”. La macchina è riuscita a battere il 68.9% dei gruppi (umani) partecipanti a una competizione di analisi dati. Ed è riuscita a farlo impiegando appena 12 ore, a fronte di mesi e mesi di lavoro che solitamente impiegano i data scientists più esperti! Tutto questo è stato possibile grazie a un’innovativa tecnica messa a punto dai ricercatori del MIT Kanter e Veeramachaneni, nota come Deep Feature Synthesis.
Deep Feature Synthesis
In ogni problema di analisi dati, innanzitutto bisogna identficare delle variabili caratteristiche. I grandi database solitamente registrano e conservano i vari tipi di dati in diverse tabelle, indicandone le relazioni attraverso degli “identificatori”. La macchina può tracciare questi identificatori, ricavandone degli “indizi” per iniziare la sua ricerca. La tecnica DFS riceve quindi come input tabelle che contengono informazioni sulle relazioni tra le variabili ed è in grado di processare i vari tipi di dati contenuti in esse. La svolta sta nel fatto che questa tecnica è stata progettata per “pensare” come un data scientist, cercando le informazioni più rilevanti nei dati forniti come input. Per fare ciò, l’algoritmo della DFS è stato ideato per investigare tutte le possibili connessioni tra dati applicando delle funzioni selettive, evidenziando infine le caratteristiche finali del problema, il tutto nel quadro di un processo iterativo. Queste “funzioni caratteristiche” sono in grado di selezionare dati potenzialmente utili da altre tabelle, dati che possono condizionare il problema e che quindi devono essere incorporate nel modello matematico. La macchina quindi segue un percorso adattivo per ottimizzare l’analisi dei dati, la creazione dei modelli e il numero di variabili, pricipalmente guardando alle relazioni tra i dati collezionati da grandi database. Le variabili e le funzioni caratteristiche finali vengono poi testate su un campione di dati con diverse combinazioni, al fine di ottimizarne l’accuratezza delle predizioni che restituiscono come output.
L’importanza dei “big data”

Il motivo per cui questa macchina potrebbe essere rivoluzionaria è legato all’uso che viene fatto oggi dei cosiddetti “big data” per spiegare e predire dei motivi ricorrenti nei dati. I modelli d’intrepretazione dei dati possono, per esempio, aiutare le aziende a predire le future abitudini dei consumatori, così come aiutare gli astronomi nell’identificare automaticamente un corpo celeste. La DSM ha delle potenzialità incredibili se si pensa all’impatto che l’analisi dei big data ha per esempio nel commercio online, nelle azioni militari, nella ricerca scientifica e nei social networks. Sinora, questi processi di identificazione delle variabili, delle loro relazioni e dell’influenza che essi hanno sul modello matematico sono stati gestiti da esperti data scientists, che unendo l’analisi dei dati all’intuizione umana sono in grado di fornire previsioni. Tuttavia questa operazione richiede tempi estremamente lunghi. LA DSM nasce proprio in risposta all’esigenza di rafforzare questo anello debole, al fine di aiutare e non di sostituire (secondo le dichiarazioni dei ricercatori del MIT) i data scientists nel loro lavoro, ottimizzandone tempi, risorse e affidabilità dei risultati.
Uomo-macchina: sfida o aiuto reciproco?

D’altro canto però è impossibile non cogliere il rinnovato contraddittorio tra macchina e uomo, tra intelligenza artificiale e intuizione primordiale. E proprio a questo proposito, i ricercatori del MIT che hanno dato vita al software hanno già avviato una start-up, la FutureLab che nella home page riporta: “Fai di più con i tuoi dati senza più data scientists”. In questo modo, il mondo dei big data diventerebbe aperto a piccole e medie aziende che, a differrenza di colossi come Google, Amazon o Facebook finora non hanno potuto permettersi esperti data scientists sul proprio libro paga. Una rivoluzione che cambierebbe il modo di fare previsioni sui dati, allargandone l’utilizzo e consentendo l’ingresso sul mercato di nuove e concorrenziali realtà economiche.
di Michele Mione
Linkografia:
http://news.mit.edu/2015/automating-big-data-analysis-1016
https://groups.csail.mit.edu/EVO-DesignOpt/groupWebSite/uploads/Site/DSAA_DSM_2015.pdf